Shared Autonomy in Unprepared Environments

Existing robot systems designed for unprepared environments generally provide one of two operating modes—full teleoperation (primarily in the field) or full autonomy (primarily in the lab). Teleoperation places significant cognitive load on the user. They must reason over both high- and low-level objectives and control the robot’s low-level degrees-of-freedom using often unintuitive interfaces, while also interpreting the robot’s various sensor streams. As a result of this continuous demand for their visuospatial attention, users typically have a severely deficient situational awareness of the robot’s operating environment. Second, the challenge of controlling each of the mobile manipulators individual degrees-of-freedom precludes motions that involve complex coordination of the joints, thereby limiting dexterity and efficiency. Tasks amenable to full autonomy are inhibited by a robot’s limited proficiency at intervention (grasping and manipulation), long-term planning, and adapting to dynamic, cluttered environments. The ability to function in the continuum that exists between full teleoperation and full autonomy would enable operations that couple the complementary capabilities of humans and robots, improving the efficiency and effectiveness of human-robot collaboration.
Shared autonomy provides a framework for human-robot collaboration that takes advantage of the complementary strengths of humans and robots to achieve common goals. It may take the form of shared control, whereby the user and agent both control the same physical platform, or human-robot teaming, whereby humans and robots operate independently towards a shared goal.
Shared Autonomy for Remote Underwater Manipulation
Scientific exploration of the deep ocean is vital for understanding natural Earth processes, but remains inaccessible to most. Dexterous sampling operations at depth are typically conducted by robotic manipulator arms onboard remotely operated vehicles (ROVs), which are directly teleoperated by pilots aboard surface support vessels. This presents barriers to access due to the infrastructure, training, and physical ability requirements for at-sea oceanographic research. Enabling shore-based participants to observe and control robotic sampling processes can reduce these barriers; however, the conventional direct-teleoperation approach is infeasible for remote operators due to the considerable bandwidth limitations and latency inherent in satellite communication. Thus, some degree of ROV autonomy is required to support remote operations.
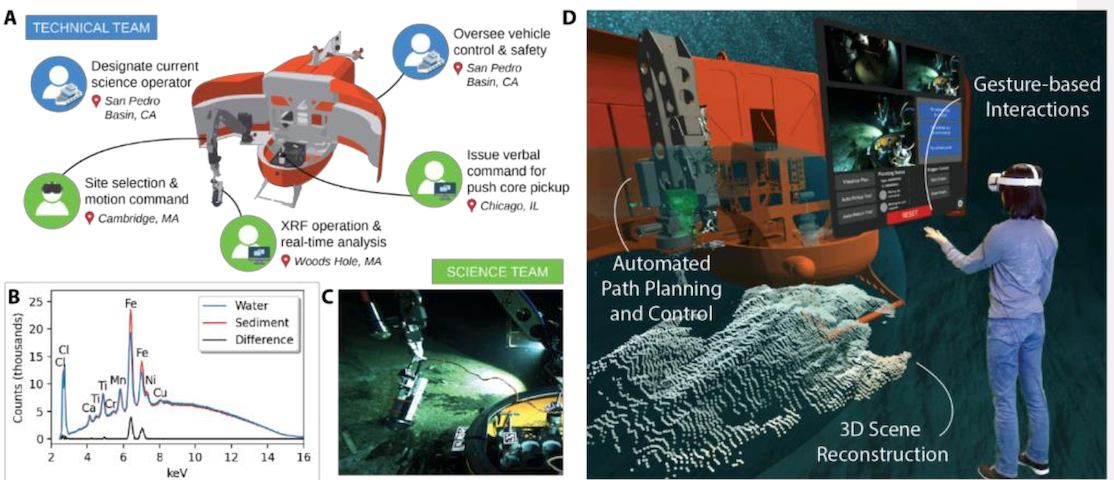
To address this need, we have been working with collaborators at the Woods Hole Oceanographic Institution (WHOI) to develop the SHared Autonomy for Remote Collaboration (SHARC) framework (Phung et al., 2023), which enables remote participants to conduct shipboard operations and control robotic manipulators using only a basic Internet connection and consumer-grade hardware, regardless of their prior piloting experience. SHARC extends current supervisory control methods (Billings et al., 2022) by enabling real-time collaboration between multiple remote operators, who can issue goal-directed commands through speech and hand gestures. SHARC couples these natural input modalities with an intuitive 3D workspace representation that segments the workspace and actions into a compact representation of known features, states, and policies. The flexibility of language enables users to succinctly issue complex commands that would otherwise be difficult to execute with conventional controllers. In addition to reducing cognitive load, the intuitive nature of speech and gestures minimizes the training required for operation and makes SHARC accessible to a diverse population of users. These natural input modalities also have the benefit of remaining functional under intermittent, low-bandwidth, and high-latency communications.
The ability to involve remote users during field operations became particularly important during the COVID-19 pandemic, when space onboard research vessels was especially restricted. During an oceanographic expedition in the San Pedro Basin of the Eastern Pacific Ocean, our remote team members operated the Nereid Under Ice (NUI) vehicle from thousands of kilometers away using SHARC’s virtual reality (VR) and desktop interfaces. The team collaboratively collected a physical push core sample and recorded in-situ X-ray fluorescence (XRF) measurements of seafloor microbial mats and sediments at water depths exceeding 1000 m, while being physically located in Chicago, Boston, and Woods Hole.
Model-free Shared Autonomy for Continuous Control
Early work in shared autonomy assumes that the user’s goals are known to the agent, which is rarely realized in practice. Recent methods instead infer the user’s goal from their actions and environment observations. These methods often assume a priori knowledge of the environment dynamics and the set of possible goals, and require access to demonstrations or the user’s policy for achieving each goal.
These assumptions can be limiting in practice, preventing the use of shared autonomy beyond simple tasks performed in structured, uncluttered environments. For example, estimating environment dynamics can be harder than learning to solve the task itself. Additionally, the goal space may be large, unknown, or may change over time. This will make it difficult or impossible to accurately infer the user’s goal or learn the user’s policy for each goal. At best, the tendency for goal inference to require the user to get close to the goal diminishes the advantages of shared autonomy. Inspired by recent work on shared autonomy, we seek to extend shared autonomy to more complicated domains through a framework in which the agent has no knowledge of the environment dynamics, the space of goals, or the user’s intent.
To that end, we developed a model-free deep reinforcement learning (RL) approach to shared autonomy (Schaff & Walter, 2020). Model-free deep RL has achieved great success on many complicated tasks such end-to-end sensor-based control, and robot manipulation and control. We avoid assuming knowledge of human’s reward function or the space of goals and instead focus on maintaining a set of goal-agnostic constraints. For example, a human driver is expected to follow traffic laws and not collide with other vehicles, pedestrians, or objects regardless of the destination or task. This idea is naturally captured by having the agent act to satisfy some criteria or set of constraints relevant to multiple tasks within the environment. Without knowing the task at hand, the robot should attempt to minimally intervene while maintaining these constraints.
Shared autonomy methods differ in the manner in which the agent augments the control of the user, which requires balancing the advantages of increased levels of agent autonomy with a human’s desire to maintain control authority. This complicates the use of standard deep reinforcement learning approaches, which traditionally assume full autonomy. In an effort to satisfy the user’s control preference, we approach shared autonomy from the perspective of residual policy learning, which learns residual (corrective) actions that adapt a nominal “hard-coded” policy. In our case, the (unknown) human policy plays the role of the nominal policy that the residual shared autonomy agent corrects to improve performance. We find this to be a natural way to combine continuous control inputs from a human and an agent.
Using this method, we are able to create robotic assistants that improve task performance across a variety of human and simulated actors, while also maintaining a set of safety constraints. Specifically, we apply our method in two assistive control environments: Lunar Lander and a 6-DOF quadrotor reaching task. For each task, we conduct experiments with human operators as well as with surrogate pilots that are handicapped in ways representative of human control. Trained only to satisfy a constraint on not crashing, we find that our method drastically improves task performance and reduces the number of catastrophic failures.
Learning Assistive Policies Without Reward
The role of the agent is to complement the control authority of the user, whether to improve the robot’s performance on the current task or to encourage/ensure safe behavior. An important consideration when providing assistance via shared autonomy is the degree to which the agent balances the user’s preference for maintaining control authority (i.e., the fidelity of the assisted behavior relative to the user’s actions), and the potential benefits of endowing more control to the agent (i.e., the conformity of the assisted behavior to that of an autonomous agent). In our work described above, we model this trade-off by using the agent to provide residual actions that correct those of the user, with the inherent assumption that the action spaces of the user and the agent are the same. By minimizing the norm of this residual correction, we encourage method to maintain the user’s control authority.
Like other recent work on shared autonomy, our method treats the user as a part of the environment, using an augmented state that includes the user’s action. Framing the problem in this way has a clear and significant advantage—it allows us to utilize the modern suite of tools for deep RL. However, these methods (including our own) have two notable limitations. First, they nominally require human-in-the-loop interaction during training in order to generate user actions while learning the assistant’s policy. Since the sample complexity of deep RL makes this interaction intractable, these methods replace the human with a surrogate policy. If this surrogate is misspecified or invalid, this approach can lead to copilots that are incompatible with actual human pilots, as we found in our previous work (Schaff & Walter, 2020). Second, these methods require access to task-specific reward during training, which may be difficult to obtain in practice.
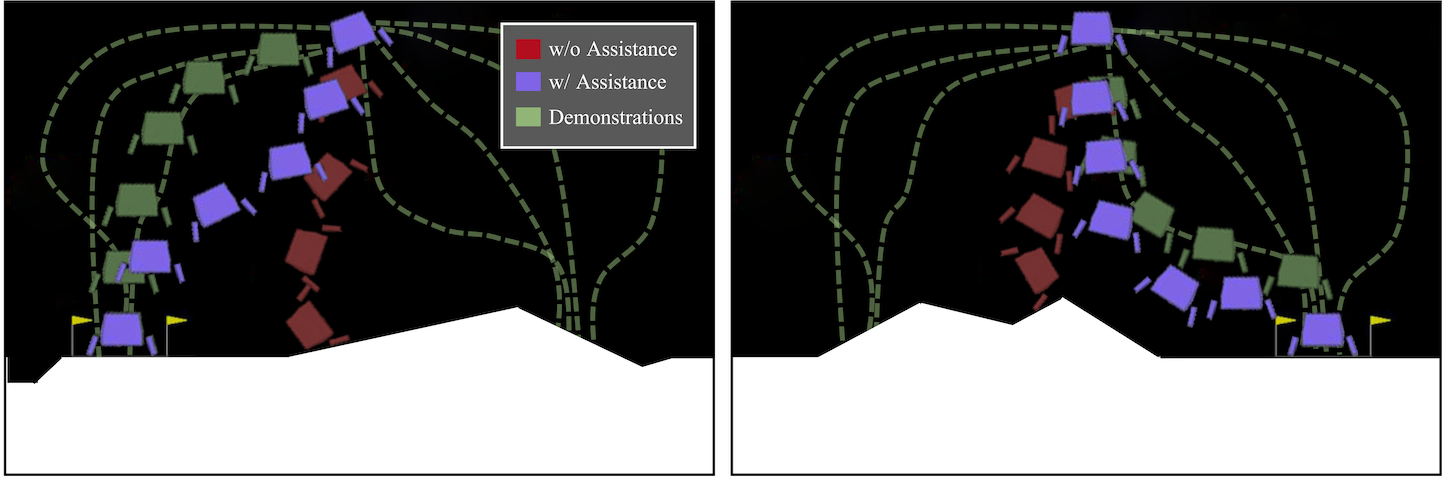
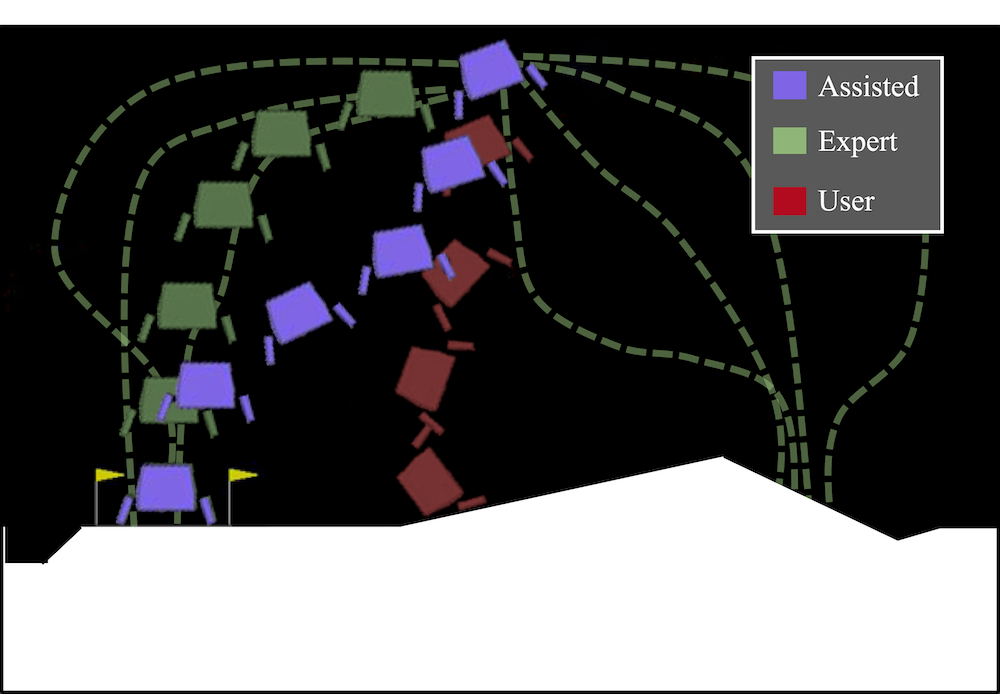
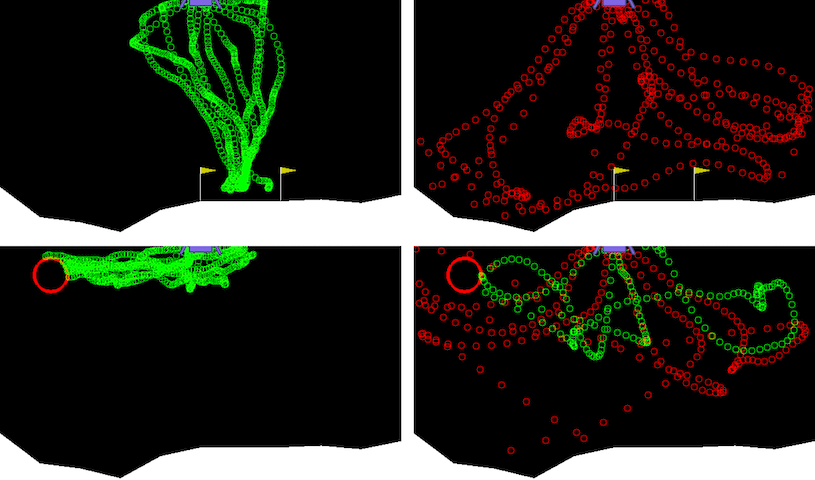
In light of these limitations, we developed a model-free approach to shared autonomy (Yoneda et al., 2023) that interpolates between the user’s action and an action sampled from a generative model that provides a distribution over desired behavior. Our approach has the distinct advantage that it does not require knowledge of or access to the user’s policy or any reward feedback during training, thus eliminating the need for reward engineering. Instead, our training process, which involves learning the generative model, only requires access to trajectories that are representative of desired behavior.
The generative model that underlies our approach is a diffusion model, which has proven highly effective for complex generation tasks including image synthesis. Diffusion models consist of two key processes: the forward process and the reverse process. The forward process iteratively adds Gaussian noise to the input with an increasing noise scale, while the reverse process is trained to iteratively denoise a noisy input in order to arrive at the target distribution. As part of this denoising process, the model produces the gradient direction in which the likelihood of its input increases under the target distribution. Once the model is trained, generating a sample from the (unknown) target distribution involves running the reverse process on a sample drawn from a zero-mean isotropic Gaussian distribution.
As we have empirically found, a direct use of diffusion models for shared autonomy ends up generating actions that ignore the user’s intent (i.e., they are low fidelity), even though the action would be consistent with the desired behaviors (i.e., high conformity to the target behaviors). To address this, we proposed a new algorithm that controls the effect of the forward and reverse process through a forward diffusion ratio that regulates the balance between the fidelity and the conformity of the generated actions. The forward diffusion ratio provides a formal bound on the extent to which the copilot’s action deviates from that of the user.
References
-
Residual Policy Learning for Shared AutonomyIn Proceedings of Robotics: Science and Systems (RSS) Jul 2020