Language Understanding for Robotics
In order for robots to work seamlessly alongside people, they must be able to understand and successfully execute natural language instructions. For example, someone using a voice-commandable wheelchair might direct it to “take me to the room across from the kitchen” or a person may command a robotic forklift to “pick up the pallet of tires and put it on the truck in receiving.” While natural language provides a flexible means of command and control, interpreting free-form utterances is challenging due to their ambiguity and complexity, differences in the amount of detail that may be given, and the diverse ways in which language can be composed.
Language Understanding as Probabilistic Inference
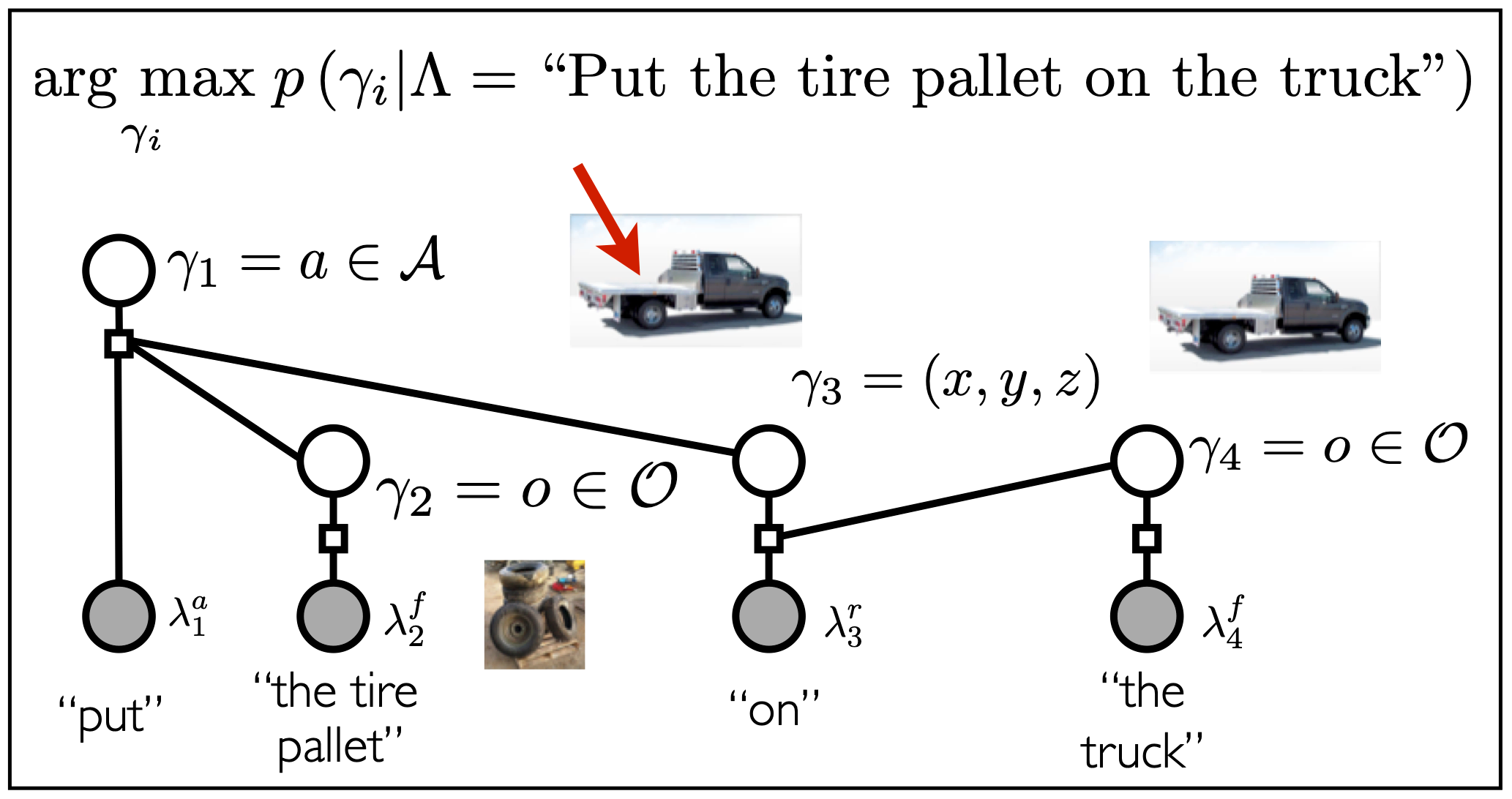
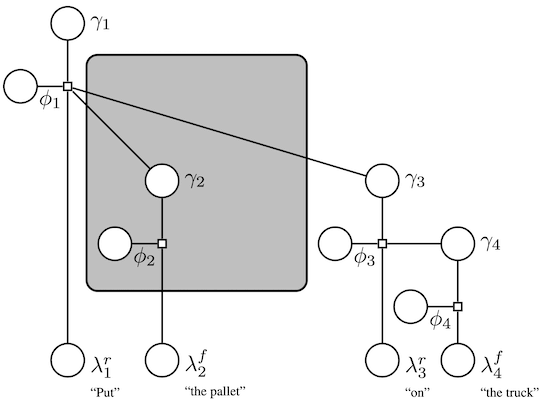
We have developed methods that frame language understanding as a problem of inference over a probabilistic model that expresses the correspondence between phrases in the free-form utterance and a symbolic representation of the robot’s state and action space (Tellex et al., 2011; Chung et al., 2015; Arkin et al., 2017). These symbols represent actions that the robot can perform, objects and locations in the environment, and constraints for an optimization-based planner. Underlying these methods is a grounding graph, a probabilistic graphical model that is instantiated dynamically according to the compositional and hierarchical structure of natural language. The grounding graph makes explicit the uncertainty associated with mapping linguistic constituents from the free-form utterance to their corresponding groundings (symbols) in the world. This model is trained on corpora of natural language utterances paired with their associated groundings, enabling the framework to automatically learn the meanings of each word in the corpora. This has the important advantage that the complexity and diversity of the language that these methods can handle is limited only by the rules of grammar and the richness of the training data. As these models become more expressive and the robot’s skills more extensive, the nature of the underlying representation becomes critical—those that are overly rich may be too complex to evaluate, while those that are simplified may not be sufficiently expressive for a given task and utterance. We have developed algorithms that enable robots to learn the appropriate fidelity and complexity of these models from multi-modal data, resulting in representations that are “as simple as possible, but no simpler”1 according to the instruction and task.
These models capture the expressivity and compositionality of free-form language and allow people to command and control robots simply by speaking to them as they would to another person. People have used these methods to communicate with a variety of robots including smart wheelchairs, voice-commandable forklifts, micro aerial vehicles, manipulators, and teams of ground robots. These models and their related inference algorithms were a core component of the Army Research Laboratory’s Robotics Collaborative Technology Alliance (RCTA), a multi-year, multi-institutional project to develop ground robots as capable teammates for soldiers (Arkin et al., 2020; Walter et al., 2022; Howard et al., 2022). By explicitly modeling the uncertainty in the grounding of a natural language utterance, the method enables novel, effective mechanisms for resolving ambiguity, e.g., by allowing the robot to engage the user in dialogue.
Language Understanding in Unknown Environments

The aforementioned language understanding methods ground free-form language into symbolic representations of the robot’s state and action space (e.g., in the form of a spatial-semantic map of the environment). These “world models” are assumed to be known to the robot. While we have developed weakly supervised methods that enable robots to efficiently learn these models from multimodal cues, robots must be capable of understanding natural language utterances in scenarios for which the world model is not known a priori. This is challenging because it requires interpreting language in situ in the context of the robot’s noisy sensor data (e.g., an image stream) and choosing actions that are appropriate given an uncertain model of the robot’s environment.
Our lab developed an algorithm that enables robots to follow free-form object-relative navigation instructions (Duvallet et al., 2014), route directions (Hemachandra et al., 2015), and mobile manipulation commands (Patki et al., 2019; Walter et al., 2022), without any prior knowledge of the environment. The novelty lies in the algorithm’s treatment of language as an additional sensing modality that is integrated with the robot’s traditional sensor streams (e.g., vision and LIDAR). More specifically, the algorithm exploits environment knowledge implicit in the command to hypothesize a representation of the latent world model that is sufficient for planning. Given a natural language command (e.g., “go to the kitchen down the hallway”), the method infers language-based environment annotations (e.g., that the environment contains a kitchen at a location consistent with being “down” a hallway) using our hierarchical grounding graph-based language understanding method (Chung et al., 2015). An estimation-theoretic algorithm then learns a distribution over hypothesized world models by treating the inferred annotations as observations of the environment and fusing them with robot’s other sensor streams. The challenge then is to choose the best actions to take such that they are consistent with the free-form utterance, based upon the learned world model distribution. Formulated as a Markov decision process, the method learns a belief space policy from human demonstrations that reasons directly over the world model distribution to identify suitable actions. Together, the framework enables robots to follow natural language instructions in complex environments without any prior knowledge of the world model.
The algorithm that explicitly learns a distribution over the latent world model has been used by voice-commandable wheelchairs and ground robots to efficiently follow natural language navigation instructions in unknown, spatially extended, complex environments (Walter et al., 2022).
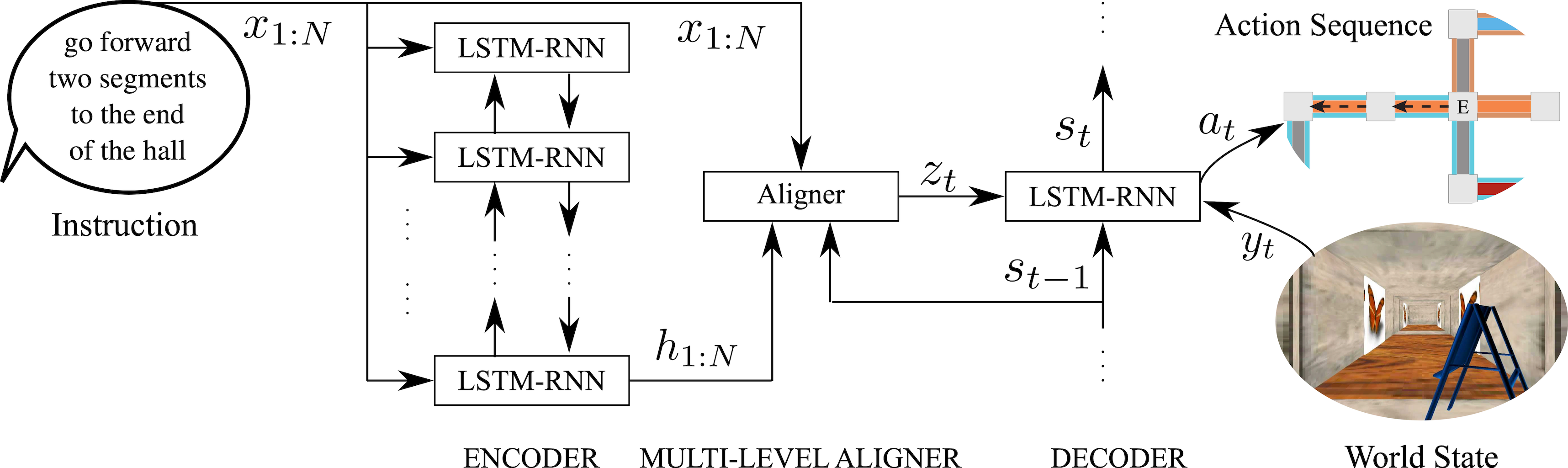
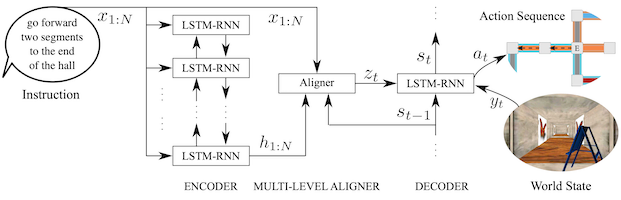
Alternatively, language understanding in unknown environments can be formulated as a machine translation problem. We developed a neural multi-view sequence-to-sequence learning model that ““translates” free-form language to action sequences (i.e., analogous to a robot ``language’’) based upon images of the observable world (Mei et al., 2016). The encoder-aligner-decoder architecture takes as input the natural language instruction as a sequence of words along with a stream of images from a robot-mounted camera, and outputs a distribution over the robot’s action sequence. More specifically, the encoder, which takes the form of a recurrent neural network, automatically learns a suitable representation (an embedding) of language, while the decoder converts this representation to a probabilistic action model based upon the history of camera images. The intermediate aligner empowers the model to focus on sentence “regions” (groups of words) that are most salient to the current image and action. In similar fashion to the grounding graph-based methods, language understanding then follows as inference over this learned distribution. A distinct advantage of this approach is that the architecture uses no specialized linguistic resources (e.g., semantic parsers, seed lexicons, or re-rankers) and can be trained in a weakly supervised, end-to-end fashion, which allows for efficient training and generalization to new domains.
Our neural sequence-to-sequence framework established the state-of-the-art performance on a dataset that serves as a benchmark evaluation in the community, outperforming methods that use specialized linguistic resources. As a testament to the generalizability of the method, we and others have demonstrated that this architecture can be adapted to perform a variety of language understanding and synthesis tasks.
References






-
A simplified version of a statement by Albert Einstein. ↩