Language Generation for Robotics
People rely on language not only to communicate intent about tasks, but also to share information about these tasks and their environments that may otherwise not be directly observable. As our partners, robots must be able to communicate in (i.e., generate) natural language. This is critical to convey information, collaborate on shared tasks, and to establish trust. While people have a lifetime of experience that allows them to infer another’s understanding of a particular environment and task and predict their behavior, we can not do the same for robots. For example, a pedestrian at a crosswalk who makes eye contact with an oncoming driver can reasonably assume that the driver has seen them and will let them cross. If the car that is approaching is instead a self-driving vehicle, however, it might be difficult for the person to infer whether the car knows they are there and, if so, whether it will stop for them to cross.
Selective Generation: Learning What to Talk About and How
Realizing robots capable of effectively using language as a means of conveying useful information is challenging, particularly given the disparity between the way that people and robots model the world. Generation requires identifying what and how much information to convey to people, a problem that is referred to as content selection. Most of what the robot understands about the world will typically not be relevant to the task, and even considering the subset that is, conveying overly detailed information can be unnatural and difficult for people to reason over. Further, different people may prefer certain types of information over others (e.g., using landmarks as opposed to distances when giving directions). A second challenge is to then synthesize this information in a natural language utterance that is both clear and succinct, a problem that is referred to as surface realization. Learning to perform these tasks jointly is challenging and, as a result, contemporary methods focus on one of the two problems, using heuristic or manual solutions for the other.
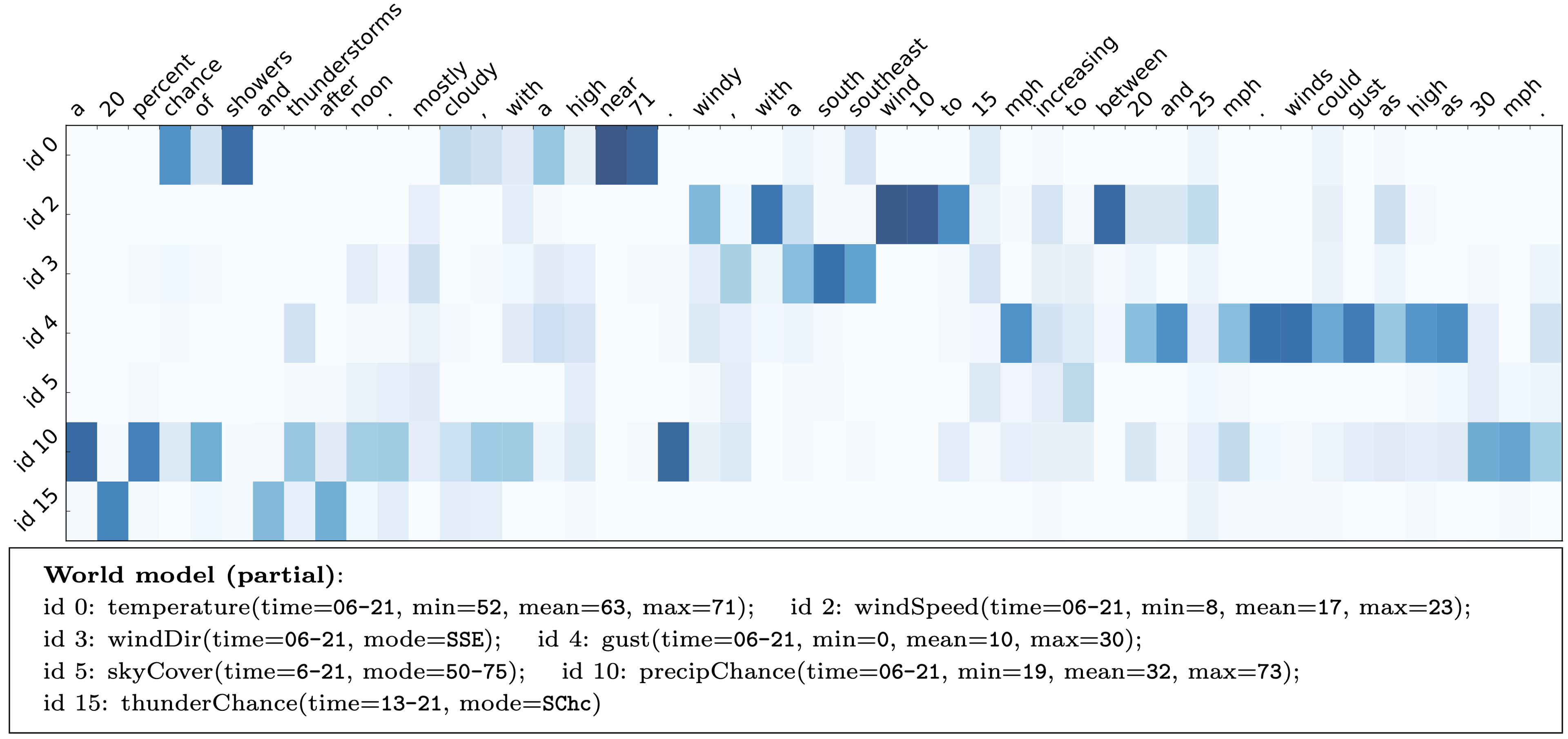
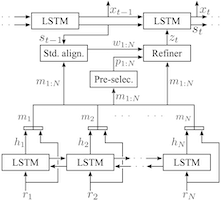
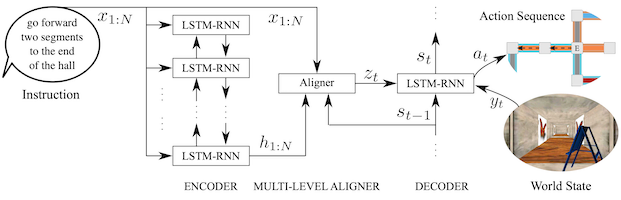
Our lab has developed models and algorithms that endow robots with the ability to generate natural language utterances that consicely convey task-relevant information. Building off our earlier neural sequence-to-sequence model for language understanding (Mei et al., 2016), we proposed an end-to-end, domain-independent neural encoder-aligner-decoder model for selective generation, i.e., the joint task of content selection and surface realization (Mei et al., 2016). Given a verbose database of facts inferred of the world (i.e., including actions and the environment), the architecture uses a novel coarse-to-fine aligner to identify the typically small subset of salient facts to convey. The neural decoder then generates a free-form description of the aligned, selected records. Key to the architecture is that it is trained in a weakly supervised manner, requiring only examples that pair a verbose set of records to an appropriate natural language description. The figure above visualizes the architecture’s ability to learn to extract noteworthy facts and to then convey these facts via natural language in the context of a benchmark task that involves producing succinct weather forecasts from a database of weather records. The neural sequence-to-sequence architecture for language generation establishes the new state-of-the-art on a series of benchmark generation tasks. Referencing the neural architecture, Wiseman et al. 20171 state that the method is able to “obtain(ing) impressive results, and motivates(ing) the need for more challenging NLG problems.” Beyond their use as a means of conveying information to their human partners, these natural language generation methods also provide an effective way to correct errors in a human’s understanding of the environment (Arkin et al., 2020), thereby resolving “knowledge dissonance.”
Generating Natural Language Instructions
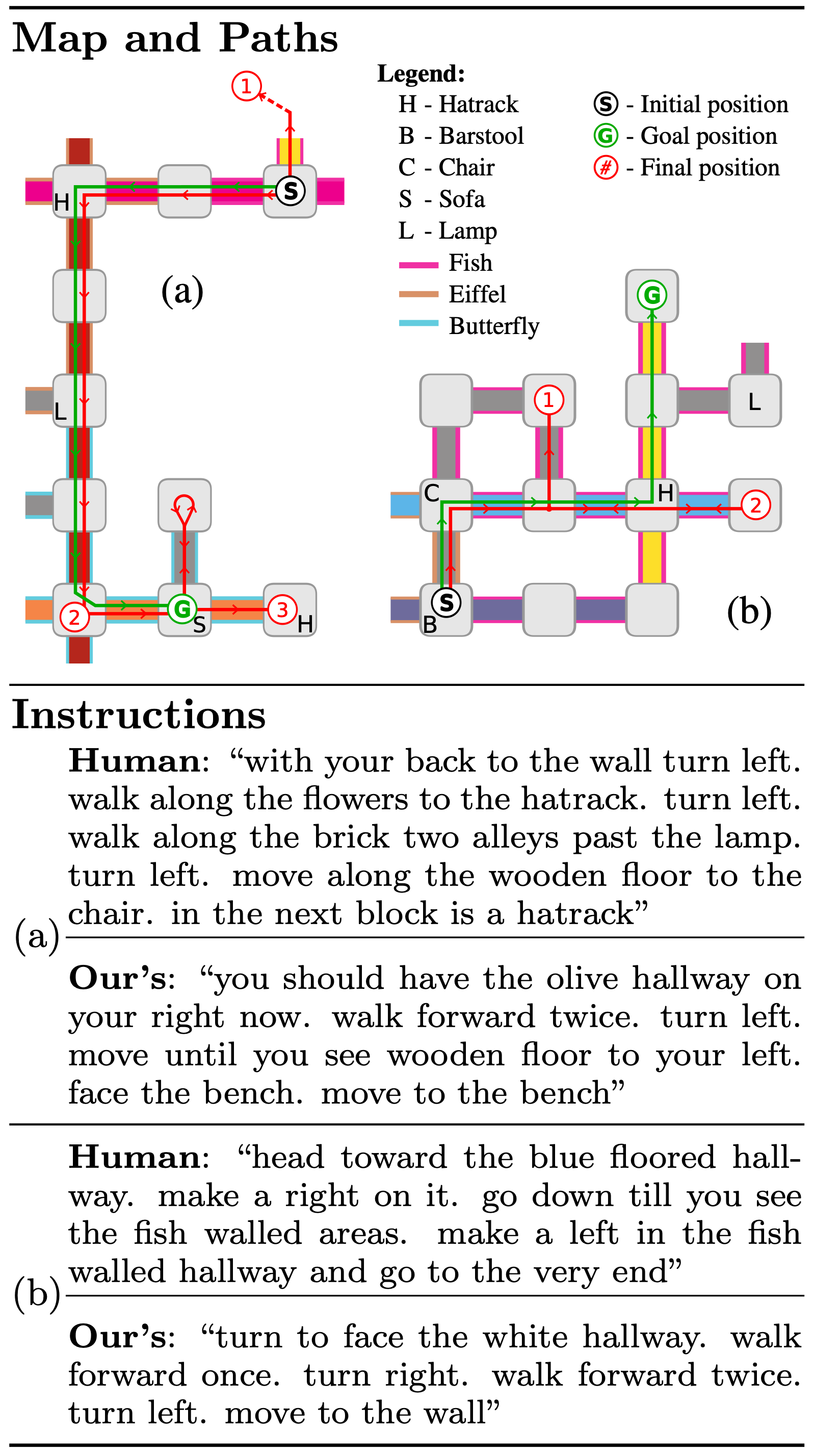
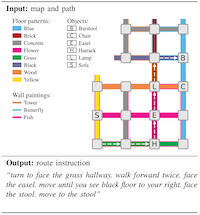
Our neural model learns to perform content selection and surface realization in an end-to-end manner directly from data. As the complexity of the domain increases, a greater amount of data becomes necessary to learn an effective selective generation model. In complex and/or data-starved settings, it is often advantageous to introduce structure into the model as an inductive bias. To that end, we proposed a framework (Daniele et al., 2017) that decouples the problems of determining what to talk about and of deciding how to convey the resulting information in natural language. The method models content selection as a Markov decision process (MDP) with a learned policy that decides what and how much to include for a given symbolic representation of the robot’s world model. This policy is trained via inverse reinforcement learning from human demonstrations, allowing it to learn which knowledge to share with people according to their preferences and the demands of the task. The framework then synthesizes a natural language description of the symbols selected by the policy using a recurrent neural network with an architecture similar to the aforementioned neural sequence-to-sequence model for language understanding. A human subjects evaluation of the framework’s ability to produce route instructions revealed that people with no prior knowledge of an environment follow instructions produced by this method more efficiently and accurately than they do instructions generated by humans. The study further found that people rate the quality of information conveyed by the synthesized instructions, the ease with which they are interpretable, and the participants’ confidence in following our instructions greater than those of human-generated directions.
References

-
Sam Wiseman, Stuart M. Shieber, and Alexander M. Rush, “Challenges in Data-to-Document Generation”, EMNLP 2017. ↩